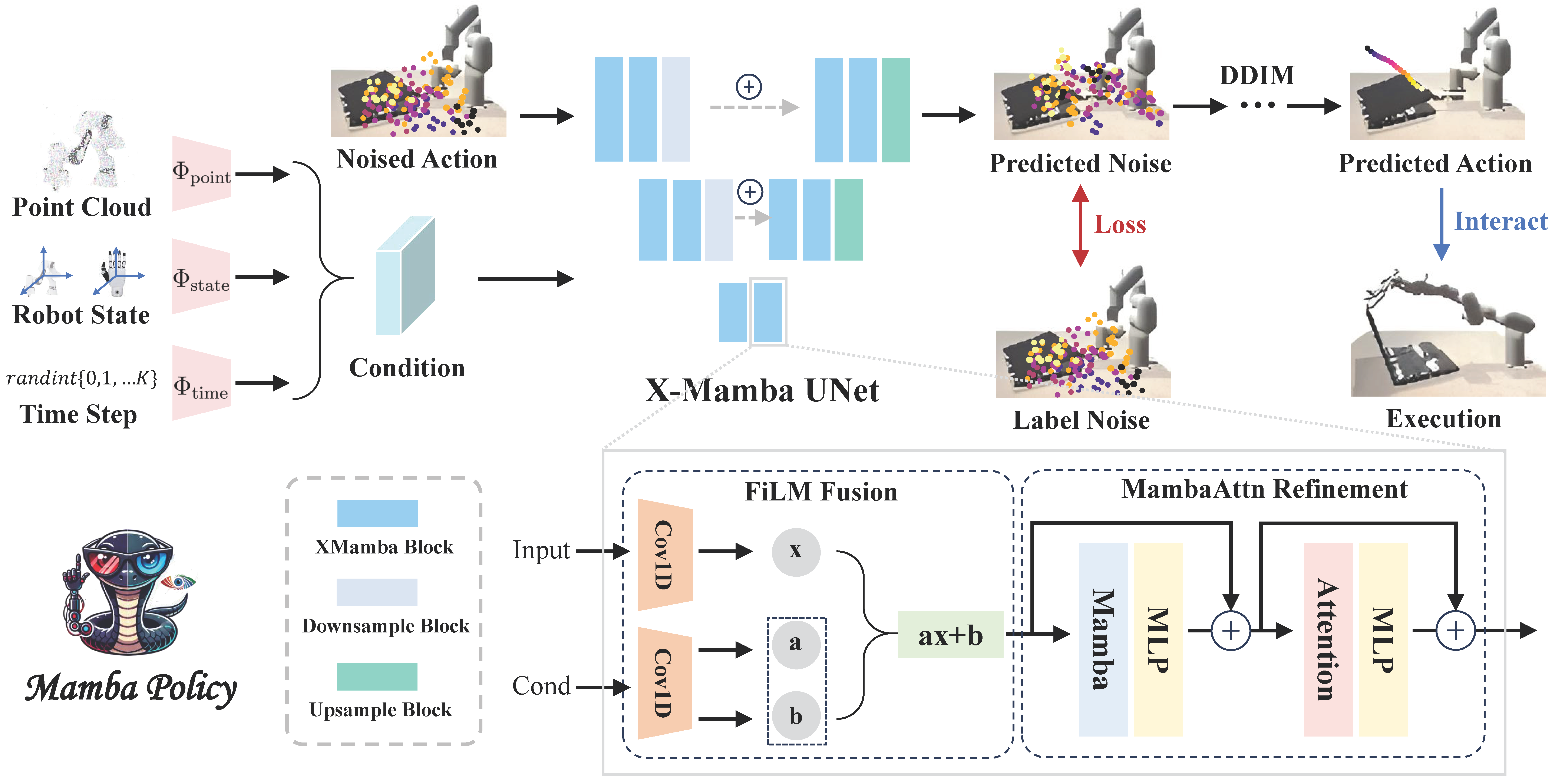
Overview of Mamba Policy. Our proposed model takes the noised action and the condition as inputs, the latter of which is composed of three parts: point cloud perception embedding, robot state embedding, and time embedding. Each of these components is processed through its respective encoder. The X-Mamba UNet is then employed to process these inputs and ultimately return the predicted noise. During training, the model is updated using MSE loss with the label noise. For validation, the model leverages DDIM to reconstruct the original action, which is then used to interact with the environment and execute different tasks.
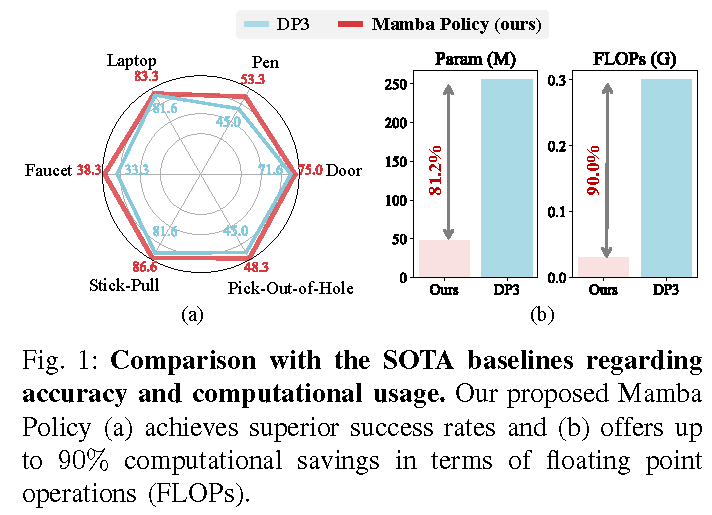
Efficieny Comparisons. Compared with DP3, our proposed Mamba Policy not only achieves superior results but also gains up to 90% and 80% computational savings regarding FLOPs and parameters number .

Quantitative Comparisons of different baselines in simulation environments. We compare our Mamba Policy with IBC, BCRNN, 3D Diffusion Policy, and Diffusion Policy in Adroit, MetaWorld and DexArt datasets. † denotes our reproduced results for fair comparison. Our proposed Mamba Policy achieves superior results across all domains.
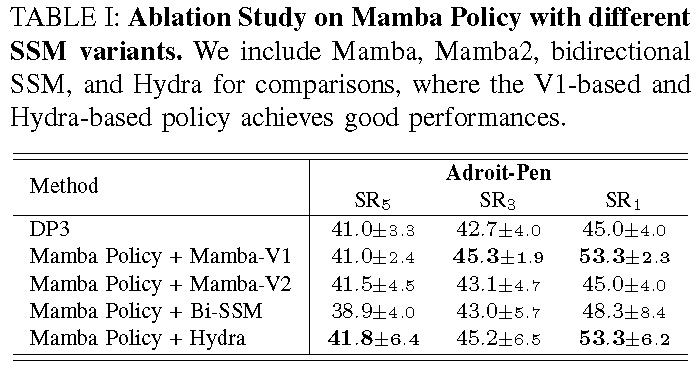
Mamba Policy with different SSM variants. We include Mamba, Mamba2, bidirectional SSM, and Hydra for comparisons, where the V1-based and Hydra-based policy achieves good performances.
@article{cao2024mamba,
title={Mamba Policy: Towards Efficient 3D Diffusion Policy with Hybrid Selective State Models},
author={Cao, Jiahang and Zhang, Qiang and Sun, Jingkai and Wang, Jiaxu and Cheng, Hao and Li, Yulin and Ma, Jun and Shao, Yecheng and Zhao, Wen and Han, Gang and others},
journal={arXiv preprint arXiv:2409.07163},
year={2024}
}